SkinDx is an android mobile app for pigmented skin lesion diagnosis. It is standalone machine learning app that uses models trained with HAM10000 dataset for diagnosis prediction without connecting to any server. The app can acheive 76.7% in accuracy.
Background
HAM10000 is a dermatoscopic image dataset for machine learning. It is created by Philipp Tschandl and others in 2018. Its aim is to solve the problem of small size and lack of diversity of available dataset of dermatoscopic images. There are 10,015 rows in the CSV file of this dataset. Each row describes a patient episode of skin disease, and each column describes an attribute eg. age, sex, localization, diagnosis and image file name of skin lesion. This dataset also contains 10,015 image files of related skin lesion.
The diagnosis is categorized into 7 groups: (1) actinic keratoses and intraepithelial carcinoma/bowen's disease (akiec), (2) basal cell carcinoma (bcc), (3) benign keratosis-like lesions (solar lentigines/seborrheic keratoses and lichen-planus like keratoses) (bkl), (4) dermatofibroma (df), (5) melanoma (mel), (6) melanocytic nevi (nv) and (7) vascular lesions (angiomas, angiokeratomas, pyogenic granulomas and hemorrhage) (vasc). The information from this dataset is used for developing android mobile app for diagnosis prediction of pigmented skin lesion.
Methods
1. HAM10000 dataset is checked for missing values and drop them out and then the remaining data is randomly divided into training and testing groups with ratio 80:20.
2.The trained model for classifying lesion image is firstly developed and tested by using transfer training from Mobilenet model.
3. The trained model from above is used to convert lesion image data into new 7 attribute columns in CSV file.
4. One-Hot encoding is used to convert categorical data.
5. The second trained model for diagnosis prediction is then developed and tested.
6. Both trained model are converted to Tensorflow lite model and are used for Android app development.
Results





The app is tested on android mobile device with 1,992 unseen testing cases for 1st order prediction. The results are as follow:
Accuracy: 76.7% (1527/1992).
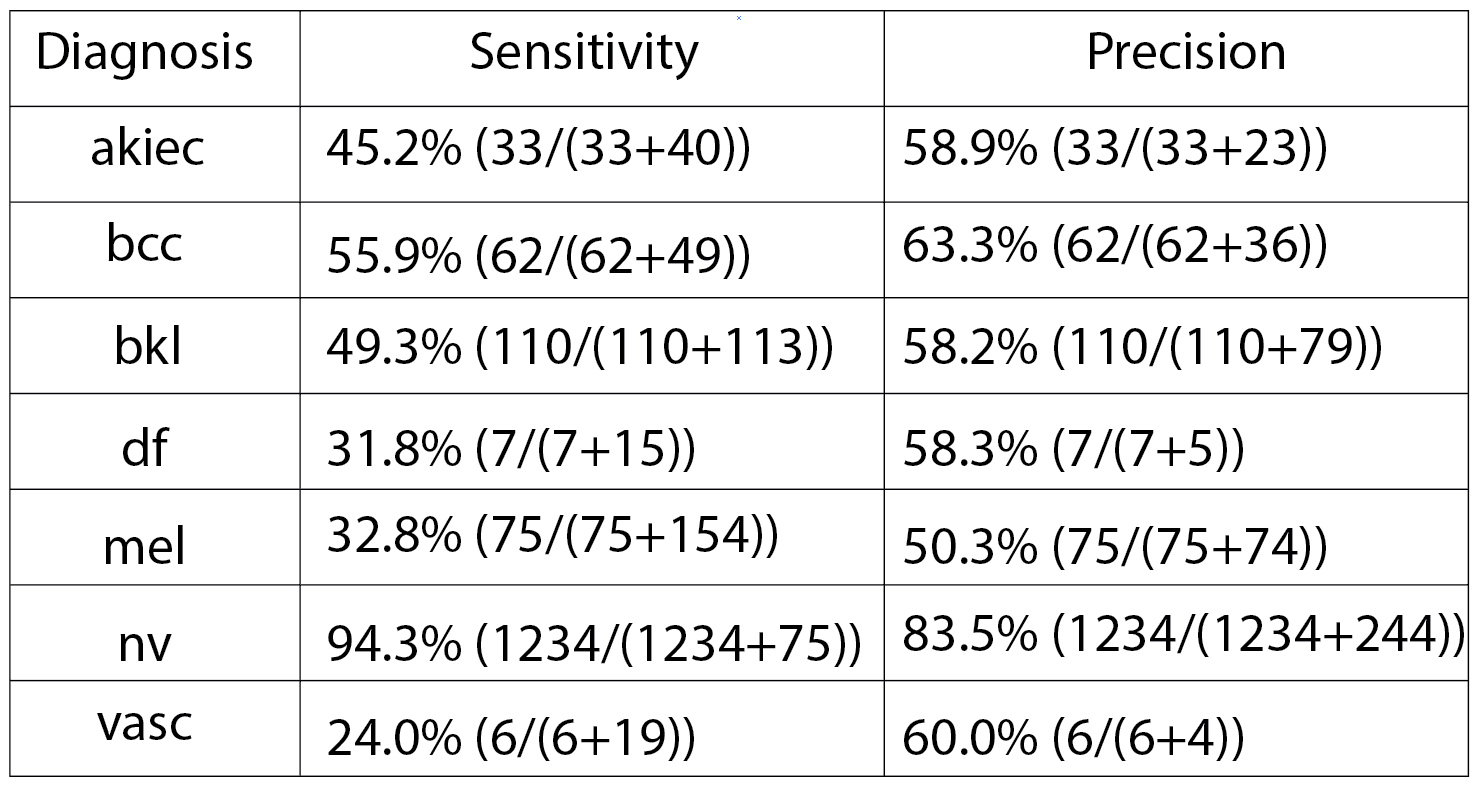
*Accuracy: correct prediction / all cases
*Sensitivity: TP / (TP + FN) *Precision: TP / (TP + FP)
*TP: True positive *FP: False positive *FN: False negative
Discussion
1. Practical use of this app depends mainly on precision score for each diagnostic group. For example if the app predicts that the skin lesion is melanoma, there is a chance of 50.3% to be correct.
2. If using only lesion image without age, sex and localization data, only 69.7% in accuracy can be achieved.
Reference
Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 5, 180161 doi:10.1038/sdata.2018.161 (2018).




















{kind=link}